Fieldnote 11: AI in Documentary Filmmaking. When the Tedious Routine Finally Lets Go
Spoiler: Applicable Beyond Filmmaking

After TIFF in September 2025, I began looking more closely at the documentary film industry. I wanted to understand, directly from documentary producers, what AI was actually doing in their workflows. When AI enters the picture, is it shaping creative decisions — or is it finally taking responsibility for the routine labour that has long constrained them?

AI as a Workflow Tool, Not a Creative Replacement
What I discovered was slightly counterintuitive: in documentary filmmaking, the central challenge has never been creativity. It is volume.
A single project can involve tens of thousands of archival photographs, hundreds of hours of footage, interviews recorded across decades, newspapers printed on degraded paper, handwritten notes, transcripts, and audio fragments — all coming from different sources, formats, and quality levels. Before any creative or editorial decision can be made, this material must first be made usable.
Historically, that work fell to humans. Teams manually described files, applied tags, entered dates, locations, and credits, and relied on memory to track what existed and where. This process routinely took weeks or months and often determined, in practice, how much material could even be considered. The bottleneck was never a lack of imagination.
This is what practitioners often refer to, without exaggeration, as the post-production swamp.
For the first time in human history, we are finally able to delegate this routine to AI. Appeared that it is not an easy setup, but still manageable for a person with no technical background.
So, what they actually started doing:
AI Organizes Images
When a photo enters the system, AI is deliberately excluded from the ingestion step. The first operation is extraction. Using standard tools such as exiftool, the system reads everything the file already contains: creation dates, photographer names, archive or accession IDs, existing captions, and any text layers added during scanning.
Embedded metadata — EXIF data, archival notes, photographer credits, archive IDs, and, where available, handwritten notes when they exist as embedded text layers — is treated as authoritative. Known facts serve as anchors.
Only after this factual grounding does AI generate a visual description. That description is deliberately constrained. It reflects what is visible in the image, who or what appears, and the setting or activity — and includes historical context only when it is supported by verified metadata.
The system is instructed conservatively:
You are an archival description system.
You must describe images factually and conservatively.
You are not allowed to invent or infer missing information.The operational prompt used in practice makes these constraints explicit:
Describe this archival photograph.
Rules:
- Use only what is visible in the image.
- Use provided metadata as factual anchors.
- Do NOT infer names, locations, or dates unless explicitly present.
- Do NOT speculate about intent, emotion, or symbolism.
- Do NOT use narrative or interpretive language.
- Output 1–2 factual sentences only.
Provided metadata:
Date: 1943
Location: Mobile, Alabama
Photographer: Russell LeeA typical output might read:
“Main Street, Mobile, Alabama, 1943. Wooden storefronts, automobiles parked along the road. Photograph by Russell Lee.”
This replaces hours of manual logging, but more importantly, it replaces inconsistency.
The critical move comes next. The description is not stored as a loose annotation in a database. It is written back into the image file itself, embedded directly in standard metadata fields. The image becomes self-describing. Wherever it travels — across systems, machines, or collaborators — it carries its identity, provenance, and meaning with it. What once depended on institutional memory becomes intrinsic to the asset.
Write-back into the file (mandatory)
exiftool \
-XMP:Description=”Main Street, Mobile, Alabama, 1943. Wooden storefronts with automobiles parked along the road. Photograph by Russell Lee.” \
-IPTC:Caption-Abstract=”Main Street, Mobile, Alabama, 1943. Wooden storefronts with automobiles parked along the road. Photograph by Russell Lee.” \
-Artist=“Russell Lee” \
-Copyright=“Library of Congress” \
image.jpgAI Organizes Video
Video is treated as a composite of images, audio, and time.
Instead of attempting to analyze every frame — a computationally wasteful and conceptually unnecessary approach — the system samples frames at regular intervals, roughly every few seconds, using standard video tools such as ffmpeg. Each sampled frame captures a moment of change without overwhelming the system.
Each sampled frame is then processed independently. A vision-capable language model generates a brief, factual caption describing what is visible. In parallel, the audio track is transcribed using speech-to-text, and the resulting transcript is time-aligned with the sampled frames.
The frame-level instruction is deliberately narrow:
Describe what is visible in this video frame.
Rules:
- Describe only visible actions, objects, and setting.
- Do NOT infer narrative meaning.
- Do NOT guess identities.
- Do NOT interpret intent or importance.
- Output one short factual sentence.This produces a synchronized representation of what is happening visually and verbally at any given moment.
Only after these elements exist — frame captions, audio transcript, and timestamps — does the system perform a reasoning pass. A language model is used to synthesize the already-extracted information, not to interpret the footage directly.
You are summarizing raw documentary footage.
Inputs:
- Frame descriptions with timestamps
- Audio transcript with timestamps
Tasks:
- Identify key moments over time
- Describe what happens sequentially
- Note recurring elements or events
Rules:
- Do NOT suggest edits.
- Do NOT evaluate importance.
- Do NOT interpret intent.
- Do NOT write narration.The result is a semantic summary of the footage. It is not an edit, not a narrative judgment, and not a creative decision. It is understanding — structured in a way that makes footage searchable and legible without replacing editorial authority.
AI Organizes Documents and Newspapers
Documents present a different challenge. Historical newspapers, letters, and official records are often damaged, poorly scanned, handwritten, or only partially relevant.
Here, human touch remains at the entry point. A researcher manually selects the portion of the document that matters — an article, a paragraph, a signature. Only that region is processed. Everything else is intentionally ignored.
OCR tools such as Tesseract (often custom-trained for historical fonts or handwriting) are used to convert the selected region into text. Language models are then applied selectively, not to reinterpret the material, but to reconstruct what OCR alone cannot reliably recover.
The reconstruction instruction is explicit:
Reconstruct the following degraded text.
Rules:
- Preserve original wording.
- Do NOT modernize language.
- Do NOT guess missing words.
- Flag unreadable sections with [illegible].When translation is required, it is handled as a separate, equally constrained step:
Translate this text literally.
Do NOT paraphrase.
Preserve sentence structure.The output is clean, searchable text explicitly tied to the exact region of the original document. This avoids false context and preserves traceability. The transcription is treated as working material, not unquestioned truth — something that can be verified, cited, or discarded by human researchers.
What AI Is Not Doing
These boundaries are explicit.
AI does not invent historical facts.
It does not generate archival footage.
It does not make creative or editorial decisions.
It does not decide what goes into the film.
Humans still choose what matters, verify facts, and shape narrative. AI’s role is narrower but consequential: ensuring that nothing valuable is lost, buried, or forgotten simply because it was too costly to process.

Automating Metadata Creation: Descriptions, Dates, Locations, and Credits
Once material is made visible and searchable, a second constraint immediately comes into focus: trust.
An image, clip, or document is only usable insofar as its context is known — when it was created, where it comes from, who made it, and under what conditions it can be used. Without this information, archival material becomes legally risky, contextually unstable, or functionally unusable, regardless of its creative value. At scale, metadata is not an accessory to documentary work; it is what determines whether material can enter the film at all.
Even once material is organized and searchable, fragility remains. Context historically lived in spreadsheets, handwritten notes, legacy catalog systems, or the heads of a few overextended researchers. As projects evolved, teams rotated, and tools changed, metadata degraded. Loss was not exceptional; it was structural. Preserving context required continuous manual effort, and even then consistency was difficult to maintain.
Building on the same ingestion logic described earlier, the system begins by extracting and consolidating whatever factual information already exists. Embedded EXIF data, archival catalog entries, accession numbers, photographer names, source references, and usage notes are treated as authoritative inputs. The goal is not reinterpretation, but stabilization — bringing dispersed fragments of institutional knowledge into a coherent, normalized form.
Only after this consolidation does AI assist with descriptive work that historically required manual logging. Visual content is translated into language in a controlled, factual manner. Photographs are described in terms of visible elements — people, environments, actions — without interpretive framing. Dates and locations are included when supported by existing documentation. When information is missing, it remains absent.
Credits and provenance are handled with the same rigor. AI is used to surface, standardize, and consistently attach creator names, institutional sources, and rights-related information to assets. What once depended on careful copying across systems becomes systematic, reducing both error and exposure.
The same design decision that governs image and video handling applies here as well: metadata does not live in a separate system. Rather than existing solely in external databases, descriptions, dates, locations, and credits are embedded directly into the files themselves. Images, videos, and audio assets become self-contained carriers of their own context. This design choice reflects a practical reality: databases are transient. Teams change. Files persist. By embedding metadata at the file level, context travels with the asset across systems, time, and organizational boundaries.
At scale, this also resolves a structural weakness of manual metadata creation: inconsistency. Human-entered descriptions vary in language, depth, and emphasis, undermining reliable discovery across large collections. AI-generated metadata, constrained by verified inputs and consistent prompts, produces a uniform descriptive layer. The value of that uniformity is functional, not aesthetic. It enables comparison, retrieval, and reuse in ways that manual processes cannot sustain.
The practical effect is a shift in starting position. Instead of confronting an unmarked mass of material, researchers and editors begin with a corpus where basic facts are already articulated and attached. Context is no longer reconstructed after the fact; it is present at the moment work begins.

Reducing Human Data Entry: Automating the Work That Once Took Months
Once material is organized and its context stabilized, a third constraint becomes visible: human attention.
In practice, logging became an unavoidable phase of work. Before an image could be searched, before footage could be evaluated, before a document could be cited, someone had to manually describe it, enter dates and locations, copy credits across systems, and cross-check sources. This work was slow, repetitive, and cognitively expensive. Weeks or months could pass before editorial work could even begin.
The issue was never that logging required expertise. It was that it consumed expertise without using it.
The guest’s workflow reframes logging as an ingestion problem rather than a human task. As material enters the system — following the same constrained ingestion logic described earlier — AI generates descriptions, transcriptions, and structural summaries automatically. Images receive factual descriptions. Video is segmented and aligned with its audio. Interviews are transcribed and time-coded. Documents become legible and searchable. What previously required sustained manual effort now occurs as a baseline condition of entry.
This does not eliminate logging as a responsibility. It changes who performs which part of it. Mechanical translation from raw material to usable information is handled by the system. Human work shifts to review, verification, and judgment — the points where expertise actually matters.
The impact is not limited to time saved. Manual logging imposes a cognitive tax. It demands prolonged focus while offering little intellectual return, increasing fatigue and error over time. When this layer is removed, attention becomes available earlier in the process. Researchers and editors encounter material when it is already legible, not while it is still opaque.
There is also a structural effect on scope. Because logging was historically expensive, teams limited how much material they could afford to process. Selection often happened early and indirectly, driven by what could realistically be logged rather than by relevance. When the cost of logging drops, that constraint loosens. Archives widen. More material can be considered before decisions are made about what matters.
At this stage of the workflow, AI changes the economics of attention. Human effort is no longer spent converting material into a usable form, but evaluating it once it already is. Thinking moves earlier. Judgment is applied where it has leverage. The work begins closer to its actual purpose.
In practice, this is where the cumulative effect of automation becomes clear. Organization makes material visible. Metadata makes it trustworthy. Removing manual logging makes it usable at scale. Together, these shifts do not accelerate creativity; they remove the conditions that delayed it.

The Real Unlock: Semantic Discovery
Even with strict constraints, AI workflows can hallucinate. When results are wrong, vague, or misaligned, the most effective diagnostic tool is a “resume work” prompt — a request that forces the system to restate what it believes it is doing.
A prompt used in practice looks like this:
“This workflow isn’t producing the expected results. I want to pause and resume this work later with another AI developer. Summarize the system’s current understanding of the task, and provide them with everything they need to know.”
These summaries are often revealing. They surface mismatches between intent and execution — not because the system failed, but because the instructions were incomplete or misinterpreted. In practice, this prompt functions less as a handoff and more as a debugging mirror.

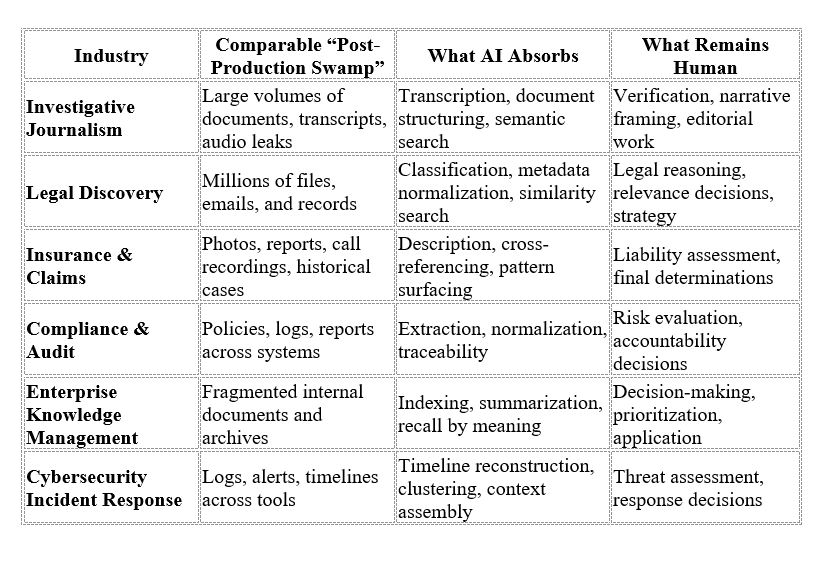
Beyond Filmmaking: A Transferable Pattern, Not a Special Case
Nothing in this workflow is unique to documentary filmmaking.
Many industries now operate under similar conditions: large volumes of heterogeneous data, high stakes around accuracy and provenance, and decision-makers whose time is consumed by preparatory labor rather than judgment.
Legal discovery, investigative journalism, historical research, insurance claims, compliance audits, cybersecurity incident response, enterprise knowledge management — all face variations of the same constraint. The work is not blocked by a lack of expertise or insight. It is blocked by the effort required to make material visible, trustworthy, and usable before decisions can even begin.
Where This Pattern Extends Beyond Filmmaking